Maximizing Application Insights with Column Prefixes
published on
In many projects, I keep encountering negative opinions towards column prefixes. Just recently I started a small poll on Twitter about this topic. And also there the opinion was 75% against column prefixes.
Column names with or without prefix? Leave a comment why you prefer the one over the other. #orclAPEX #oracle #Database
— Maik Michel (@Maik__Michel) June 24, 2023
I can't even say exactly where this comes from. But I suspect more from the non-SQL /PLSQL side. In other languages like Java the use of prefixes makes no sense at all and yes, if you have an object relational mapper that generates code that is prefixed, it's pretty ugly.
Here in my example it is primarily about Oracle SQL/PLSQL and also APEX applications. I think we agree that there should be some rules regarding the naming convention, meaning the notation of columns and objects within the database. From many projects I know the following rules:
- No prefixes
- Columns with PrimaryKey are name by tablename_ID
- Columns which are linked by a ForeignKey relation are named by their own PrimaryKey column
Here is an example with the tables PROJECTS and TASKS, which are related to each other.
create table projects (
projects_id number not null, -- primary key
name varchar2(250 char) not null,
start_date date,
end_date date,
created_at date not null,
created_by varchar2(250 char) not null,
modified_at date not null,
modified_by varchar2(250 char) not null
);
create table tasks (
tasks_id number not null, -- primary key
name varchar2(250 char) not null,
hours_estimates number(5),
projects_id number not null, -- foreign key
created_at date not null,
created_by varchar2(250 char) not null,
modified_at date not null,
modified_by varchar2(250 char) not null
);
With this principle it is noticeable that we must take in a select statement, which works with a join, definitely an alias per table, since here the ID columns are never unique. In addition, the audit columns are also named identically, which makes the simple joining of two tables much more complicated.
Another impact, and in my opinion a big one, is the maintainability of the database PL/SQL code that results from such naming. So let's imagine a project where there are a lot of packages and additionally a lot of APEX pages where the corresponding information is displayed or edited. And now we have to change the logic concerning the column "name" of the Tasks table. We have to check all places in the code where this column is used.
That is really annoying
And now how about a naming convention that provides column prefixes?
The following rule has worked well in all my projects:
- Each column of a table gets assigned a prefix that is unique per table. (The naming / glossary becomes part of the source code and is directly visible to all developers)
- Columns with PrimaryKey get the prefix and ID (xyz_id)
- Columns which are linked by a ForeignKey relation are named like their PrimaryKey column but with Prefix.
Thus each column is unique
create table projects (
prj_id number not null, -- primary key
prj_name varchar2(250 char) not null,
prj_start date,
prj_end date,
prj_created_at date not null,
prj_created_by varchar2(250 char) not null,
prj_modified_at date not null,
prj_modified_by varchar2(250 char) not null
);
create table tasks (
tsk_id number not null, -- primary key
tsk_name varchar2(250 char) not null,
tsk_hours_estimates number(5),
tsk_prj_id number not null, -- foreign key
tsk_created_at date not null,
tsk_created_by varchar2(250 char) not null,
tsk_modified_at date not null,
tsk_modified_by varchar2(250 char) not null
);
Which prefixes are chosen and whether they are 3, 4 or 5 digits must be made dependent on the project size. Important is a kind of glosar, in which the mapping can be looked up.
Besides the actual advantage for the impact analysis, there is also the advantage in the naming to exclude certain words as column names. I cannot name a column end in SQL. I would have to surround this column with double quotation marks or name it something else.
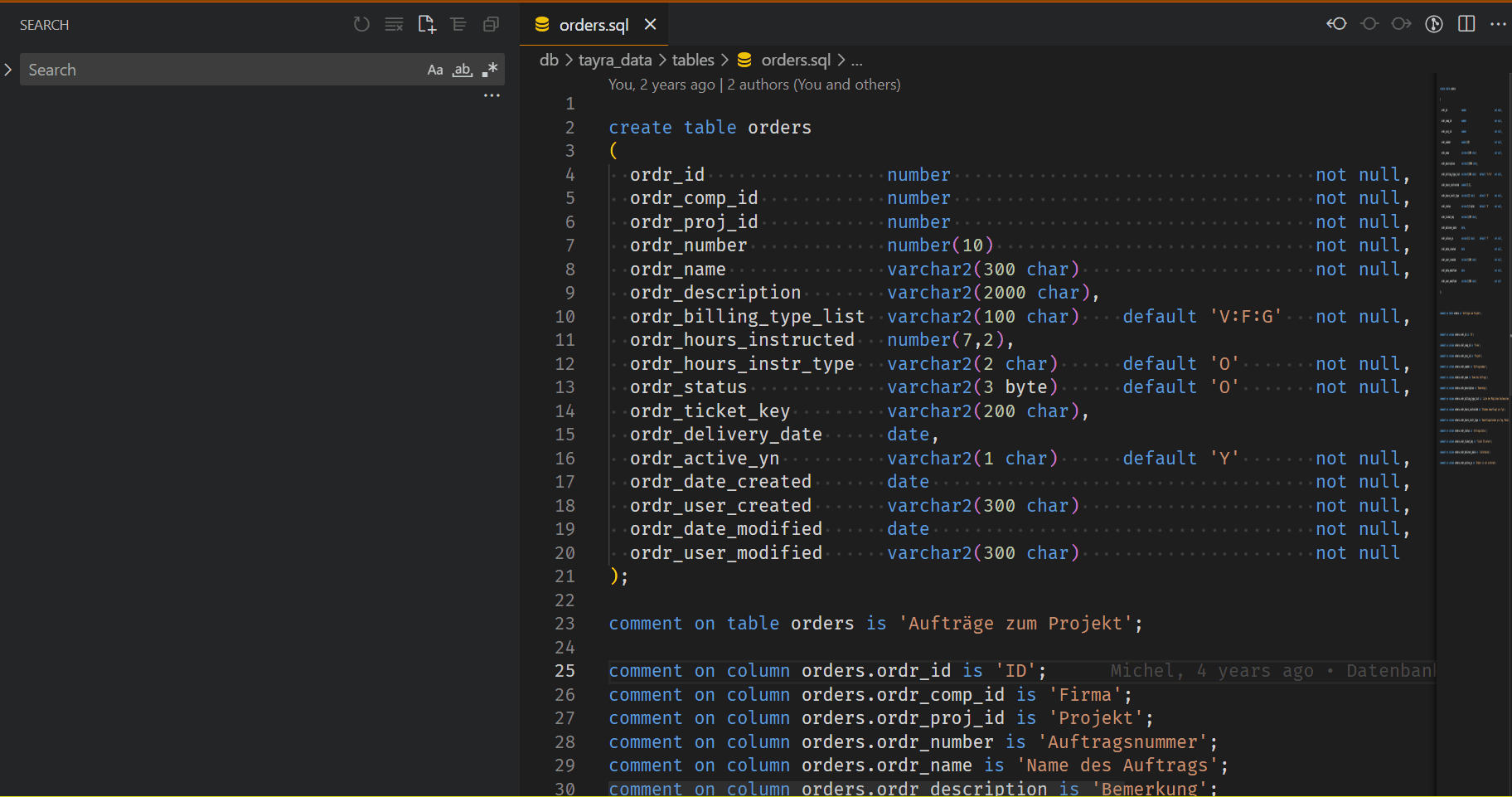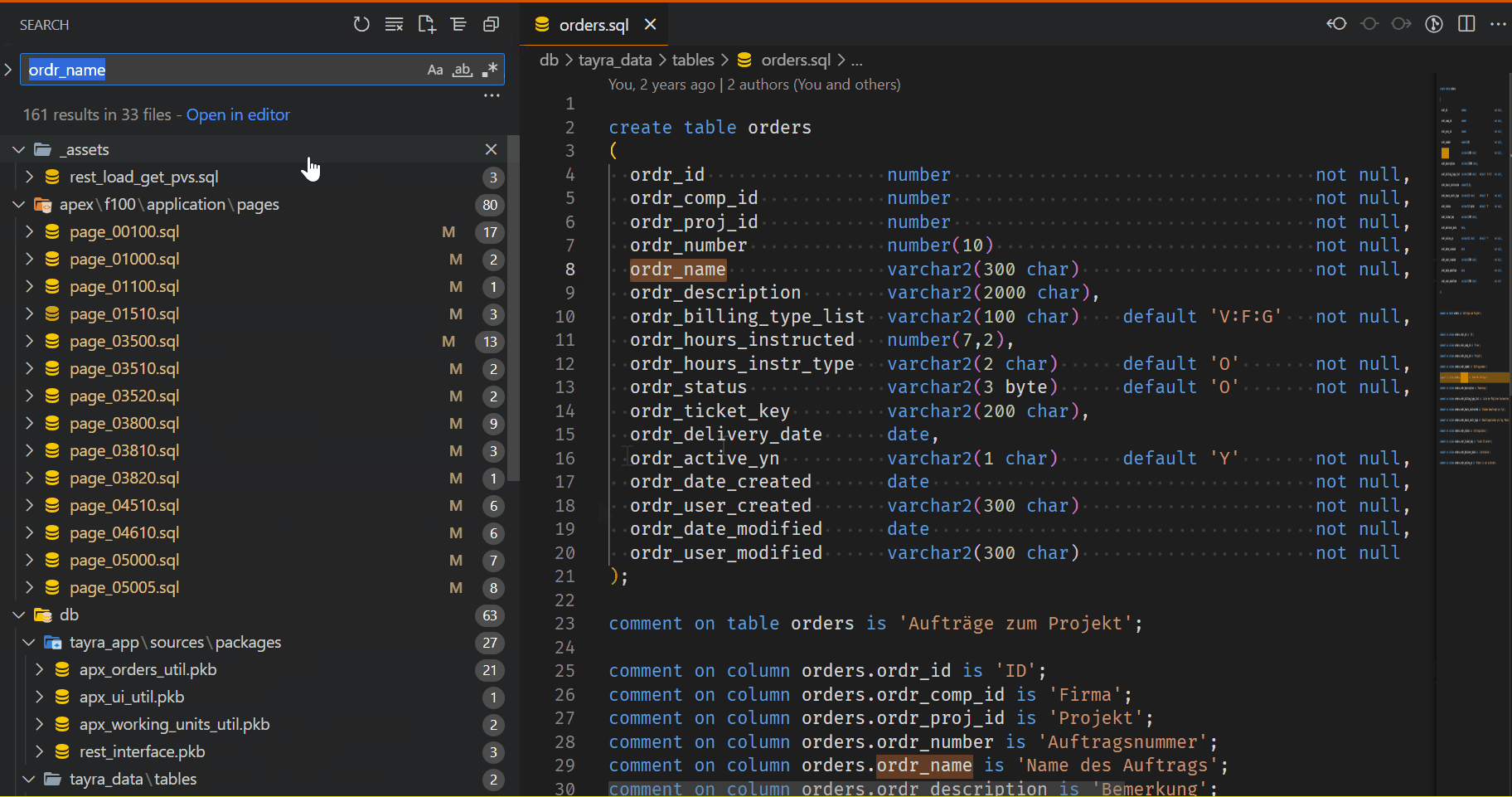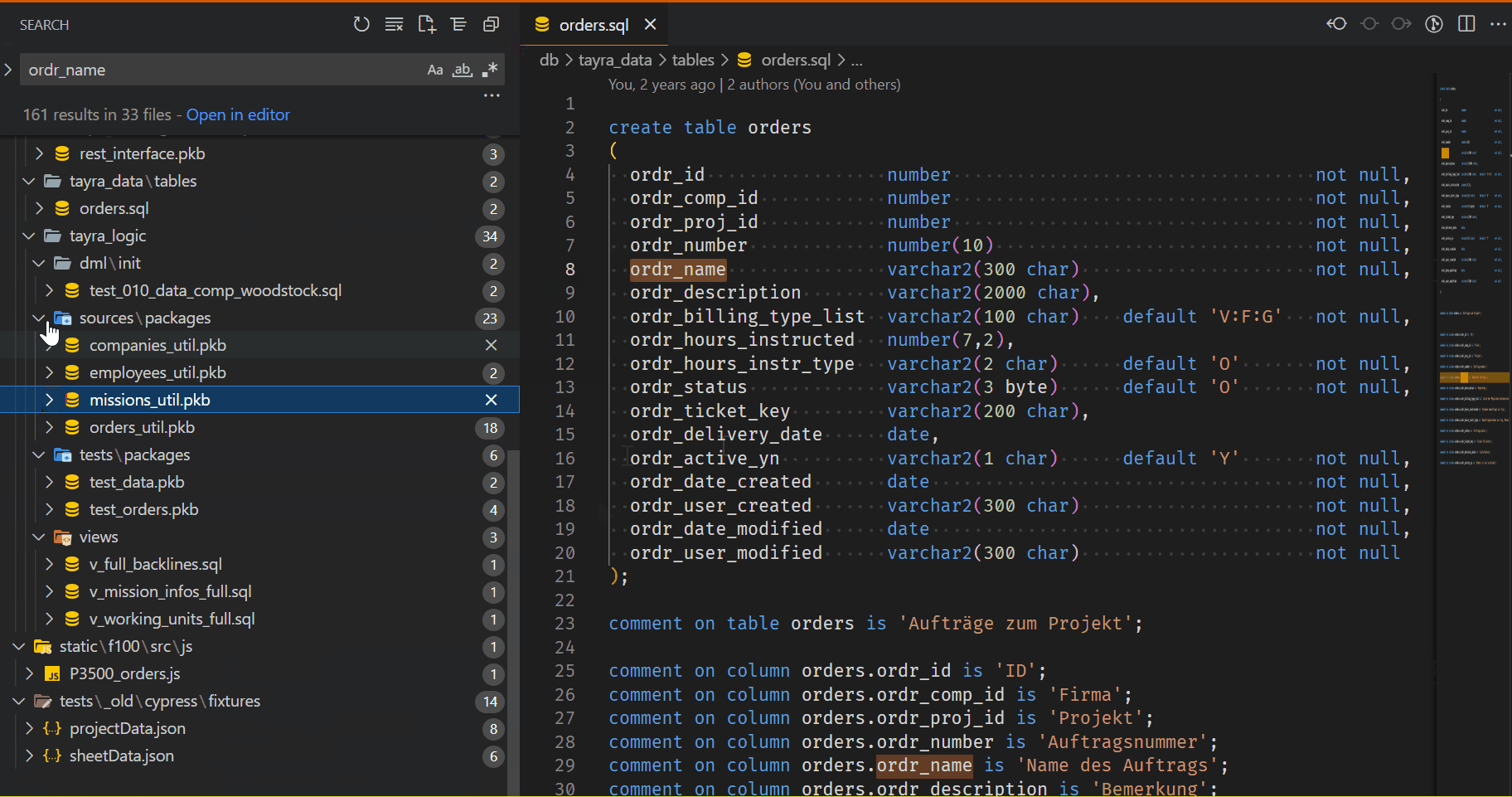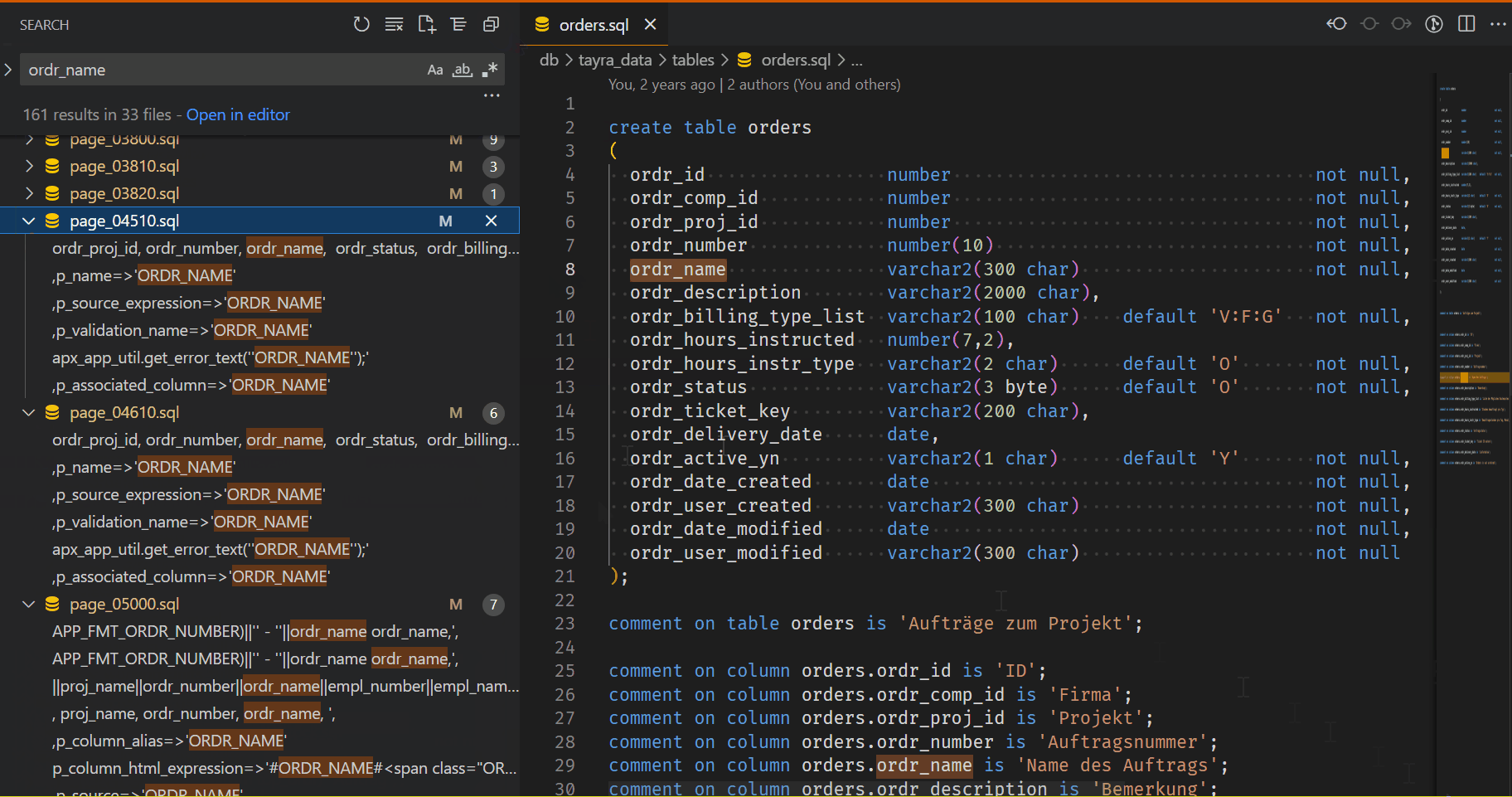
And now we can look for our Impact: